参考:
k8s-2hours: kubernetes两小时入门教程
b站视频
视频文档作者:一小时技术精讲 (感谢大佬!)
k8s官方中文网
注意:
有些yaml的注释是在写文档的时候补上的 如果遇到缩进(或者未知符号)的问题 请看一下是不是哪个注释我手瘸按了tab(OwO)
架构
使用vagrant创建
或者
在 Windows 下使用 WSL2 搭建 Kubernetes 集群-腾讯云开发者社区-腾讯云 (tencent.com)
使用wsl+kind搭建 wsl版本不能太旧 可以使用下面命令更新
1
2
3
4
5
6
# --update 更新
# --web-download 从github下
wsl --update --web-download
# 开启systemd
echo -e "[boot]\nsystemd=true" | sudo tee -a /etc/wsl.conf
关于创建 k8s官网 上有更详细的说明 有空的话更希望看一下那边
因为一些历史遗留问题 在国内可能在任何阶段遇到网络问题 所以放在前面
docker加速:[配置 docker 加速服务-阿里云开发者社区 (aliyun.com)](https://developer.aliyun.com/article/929177#:~:text= 配置 docker 加速服务 2022-05-20 6309 举报 简介: 加速器推荐,客户端 推荐安装 1.10.0 以上版本的 Docker 客户端,参考文档 docker-ce 2.)
有些官方示例中的镜像的仓库我们是上不去的 比如gcr.io 我们应该使用比如阿里云提供的对应的镜像 来替换掉配置文件中image配置项
pull 镜像慢 可以尝试手动加载 详见[cri导入导出](#cri 容器镜像导入导出)
是可以在 Kubernetes 中创建和管理的、最小的可部署的计算单元
(就像在豌豆荚中)是一组(一个或多个)容器
这些容器共享存储、网络、以及怎样运行这些容器的声明 Pod 中的内容总是并置(colocated)的并且一同调度,在共享的上下文中运行 Pod 所建模的是特定于应用的 “逻辑主机”, 其中包含一个或多个应用容器,这些容器相对紧密地耦合在一起 在非云环境中,在相同的物理机或虚拟机上运行的应用类似于在同一逻辑主机上运行的云应用
handbook/05.Pod(容器集).md · jeff-qiu/k8s-2hours - Gitee.com
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# image后面可以指定版本 和docker一样如 nginx:1.23
kubectl run mynginx --image= nginx
# 查看Pod
kubectl get pod
# 描述
kubectl describe pod mynginx
# 查看Pod的运行日志
kubectl logs mynginx
# 显示pod的IP和运行节点信息
kubectl get pod -owide
# 使用Pod的ip+pod里面运行容器的端口
curl 10.42.1.3
# 进入容器 同docker
kubectl exec mynginx -it -- sh
kubectl get po --watch
# -it 交互模式
# --rm 退出后删除容器,多用于执行一次性任务或使用客户端
# sh 也有可能是bash 看它 bin里有啥
kubectl run mynginx --image= nginx -it --rm -- sh
# 删除
kubectl delete pod mynginx
# 强制删除
kubectl delete pod mynginx --force
如果因为网络问题出错请按照该教程配置自己的docker加速
镜像加速
[阿里云用户镜像加速地址在哪里_chushiyunen的博客-CSDN博客](https://blog.csdn.net/enthan809882/article/details/104764229#:~:text= 阿里云镜像加速地址 1. 登录 阿里云 账号 登录 地址 :https%3A%2F%2Faccount.aliyun.com%2Flogin%2Flogin.htm,如果没有账号就注册一个 2. 登录后点击【控制台】 3. 搜索【容器 镜像 服务】 4.)
修改/etc/rancher/k3s/registries.yaml文件
1
2
3
4
mirrors :
docker.io :
endpoint :
- "https://xxx.mirror.aliyuncs.com/"
把下面的加速地址换成自己的
大概率不是配置问题 而是运行的pod没有一个持续运行的任务
比如 kubectl run alpo --image=alpine
解决方法
换一个镜像或者给它塞一个持续运行的任务
是对ReplicaSet和Pod更高级的抽象
它不是一个具体的东西 而是 告诉集群管理者"我需要x个 y pod" 这样的感觉
它使Pod拥有多副本,自愈,扩缩容、滚动升级等能力
rs ReplicaSet(副本集)是一个Pod的集合。 它可以设置运行Pod的数量,确保任何时间都有指定数量的 Pod 副本在运行。 通常我们不直接使用ReplicaSet,而是在Deployment中声明
1
2
3
4
5
6
7
8
# 创建名为 ng-deploy 的deployment,镜像为nginx:lastes,部署3个运行alpine的Pod
kubectl create deployment ng-deploy --image= nginx --replicas= 3
# 查看deployment
kubectl get deploy
# 查看replicaSet
kubectl get rs
# 删除deployment
kubectl delete deploy nginx-deployment
1
2
3
4
5
6
7
8
9
10
# 手动缩放 把数量扩大到5
kubectl scale deploy ng-deploy --replicas= 5
# 自动缩放 设置最小数量为3(不写min默认为1) 最大数量为8 且设置cpu利用率为75%
# 这个 '/'大概等价于 ' ' 感觉 / 的地方都可以直接打空格
kubectl autoscale deploy/ng-deploy --min= 3 --max= 8 --cpu-percent= 75
# hpa 动态伸缩
kubectl get hpa
# 删除动态伸缩
kubectl delete hpa ng-deploy
注: 我玩的时候貌似 delete deploy之后 上面的动态伸缩还在 需要手动删除
1
2
3
4
5
6
7
8
9
10
11
# 创建一个deploy 镜像为nginx的alpine版本
kubectl create deploy ngs --image= nginx --replicas= 3
# 查看版本
kubectl get deploy/ngs -owide
# 另起窗格 查看过程
kubectl get rs --watch
#更新容器镜像
kubectl set image deploy ngs nginx = nginx:alpine
#滚动更新
kubectl rollout status deploy ngs
1
2
3
4
5
6
#查看历史版本
kubectl rollout history deployment/nginx-deployment
#查看指定版本的信息
kubectl rollout history deployment/nginx-deployment --revision= 2
#回滚到历史版本
kubectl rollout undo deployment/nginx-deployment --to-revision= 2
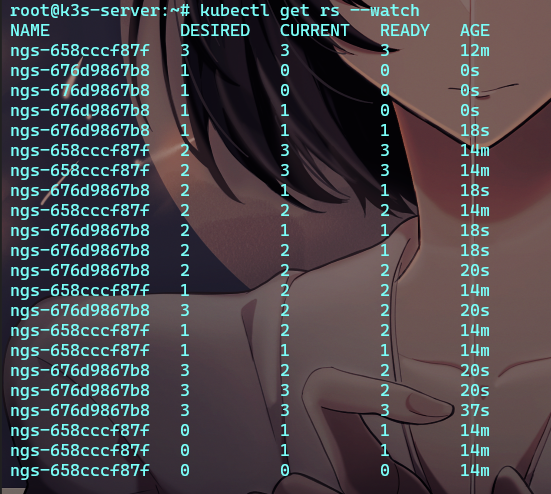
运行结果:
这里能看到它是…7f 和…b8 两个rs的更迭
7f是未进行版本迭代前的集合 b8则是迭代后的集合
步骤如下:
b8创建
b8添加一个节点 添加完成后
7f删除一个节点
重复 直到7f的三个节点全部被替换
对于deploy:
1
kubectl get deploy --watch
可以看到 它实际上就是加入一个新版本pod 关掉一个旧版本pod 重复 直到完成更迭
sts | StatefulSet | Kubernetes
类似于deploy 不同的是 sts会按照 stsname-id(这个id会从0开始自增 类似go的iota)
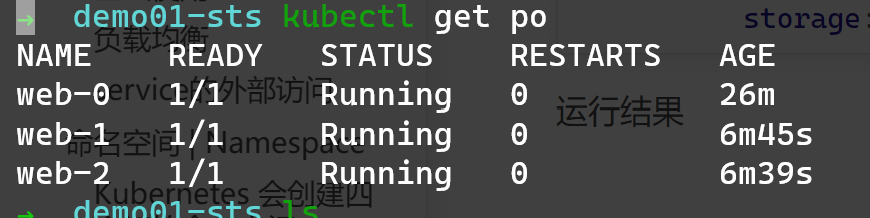
比如 名为mysts的sts指定pod数量为3
那么它将依次创建: mysts-0, mysts-1, mysts-2
缩容为2则会删除 mysts-2
再扩容到3后 它会再重新生成一个新的pod命名为mysts-2再加入集合
相比deploy它保证了每个pod有固定指向的名称
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
selector :
matchLabels :
app : nginx
serviceName : "nginx"
replicas : 3 # 默认值是1
# minReadySeconds: 10 # 默认值是 0
template :
metadata :
labels :
app : nginx
spec :
terminationGracePeriodSeconds : 10
containers :
- name : nginx
image : nginx:latest
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
# 不指定sc 使用默认的sc创建pvc
# storageClassName: "my-storage-class"
resources :
requests :
storage : 0. 5Gi
运行结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 使用上面的deploy ngs来建立服务 服务名是 ngs-service 将(集群内部的)本地端口8080 映射到服务提供者(pods)的80端口
kubectl expose deploy ngs --name= ngs-service --port= 8080 --target-port= 80
# 查看服务 可以看到ngs-service的DNS是10.43.121.100
kubectl get svc
# 或者查看详细信息
kubectl describe svc ngs-service
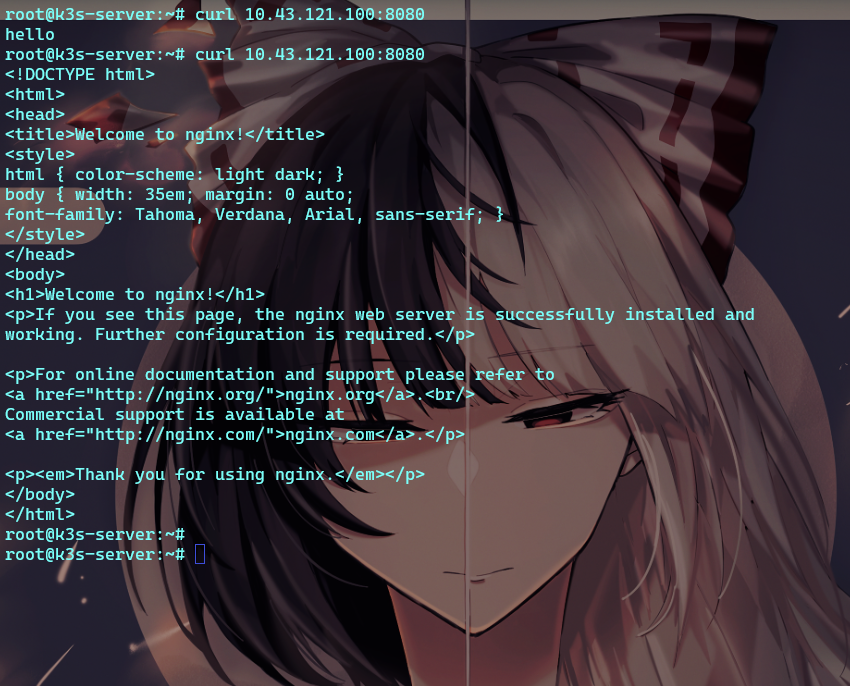
# curl 直接请求 得到nginx默认的提示页
curl 10.43.121.100:8080
# 创建一个临时pod 在该pod中可以直接通过服务名来访问svc
kubectl run test -it --image= nginx --rm -- bash
# 在pod中使用服务名或地址均可以访问到该页面
curl ngs-service:8080
使用 kubectl exec po 进入其中一个pod
将其中一个nginx的index修改为hello
root@k3s-server:~# kubectl exec ngs-676d9867b8-xdk7s -it – sh
/ # cd /usr/share/nginx/html
/usr/share/nginx/html # echo “hello” > index.html
/usr/share/nginx/html # cat index.html
hello
/usr/share/nginx/html # exit
然后访问服务
curl 10.43.121.100:8080
此时 hello以及 nginx的默认主页 均有概率出现
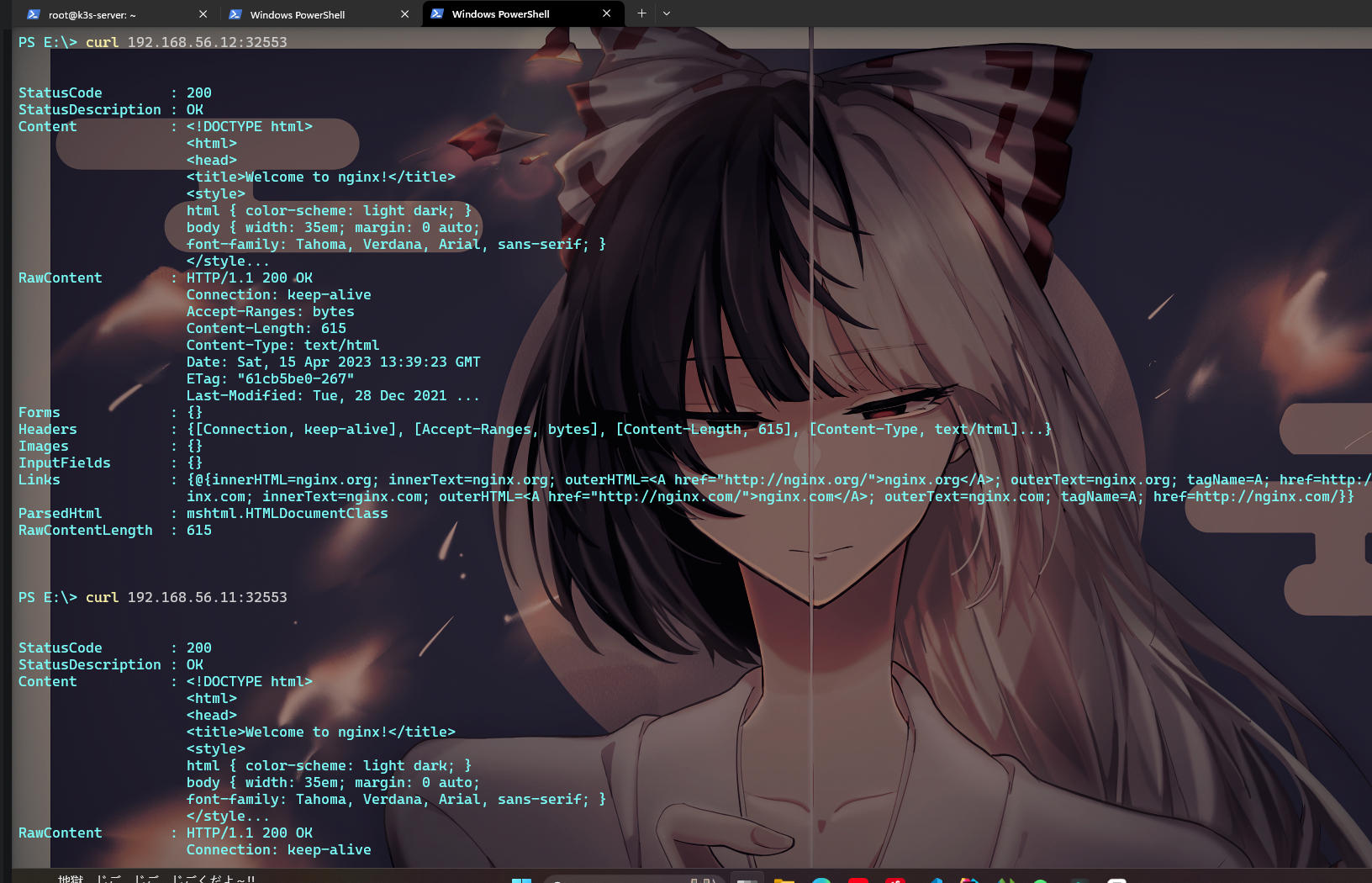
再创建一个服务 指定服务类型为 NodePort
1
kubectl expose deploy ngs --name= ngs-svc1 --port= 8081 --target-port= 80 --type= NodePort
可以看到 新加的服务 ngs-svc1后面有一个端口映射 此时我们可以访问任意node:32553在外部访问它
这里使用的是外部的windows系统的powershell请求 能正确得到结果
service可选类型
ClusterIP:默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问
NodePort:将Service通过指定的Node上的端口暴露给外部,访问任意NodeIP:nodePort都将路由到ClusterIP
LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到:NodePort,此模式只能在云服务器上使用
ExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion : v1
kind : Service
metadata :
name : ngs-svc
spec :
type : NodePort
selector :
# 标签选择器 选择提供服务的pod
# 注意区分大小写
app : nginx
ports :
# port 服务端口
- port : 80
# targetPort 容器端口
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
targetPort : 80
# 可选字段
# 对外公开的端口
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort : 30007
无头服务 Cluster IP(spec.clusterIP) 的值为"None"的svc
svc对一堆svc实现负载均衡 但不是所以集群都需要负载均衡
比如 一个mysql集群中 数据每次被负载均衡分配去不同的地方大概率是不合适的
又比如kubernetes部署某个kafka集群 客户端需要的是一组pod的所有的ip 负载均衡在这里有些多余
它不再对外提供ip(重建pod时ip会变) 而是提供稳定的DNS(类似sts那样的稳定不变)
sts那个例子中就使用无头服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
apiVersion : v1
kind : Service
metadata :
name : nginx
labels :
app : nginx
spec :
ports :
- port : 80
name : web
clusterIP : None
selector :
app : nginx
---
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : web
spec :
selector :
matchLabels :
app : nginx
serviceName : "nginx"
replicas : 3 # 默认值是1
# minReadySeconds: 10 # 默认值是 0
template :
metadata :
labels :
app : nginx
spec :
terminationGracePeriodSeconds : 10
containers :
- name : nginx
image : nginx:latest
ports :
- containerPort : 80
name : web
volumeMounts :
- name : www
mountPath : /usr/share/nginx/html
volumeClaimTemplates :
- metadata :
name : www
spec :
accessModes : [ "ReadWriteOnce" ]
# 不指定sc 使用默认的sc创建pvc
# storageClassName: "my-storage-class"
resources :
requests :
storage : 0. 5Gi
1
2
3
4
➜ demo01-sts kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT( S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 7h
nginx ClusterIP None <none> 80/TCP 73m
可以在pod内部的 /etc/hosts里看到
1
2
3
4
5
6
7
8
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.244.1.6 web-0.nginx.default.svc.cluster.local web-0
DNS为web-0.nginx.default.svc.cluster.local
命名规则为pod名称.svc名称.ns名称.svc.cluster.local
命名空间(Namespace) 是一种资源隔离机制,将同一集群中的资源划分为相互隔离的组。
命名空间可以在多个用户之间划分集群资源(通过资源配额 )。
同一命名空间内的资源名称要唯一,但跨命名空间时没有这个要求。
命名空间作用域仅针对带有名字空间的对象,例如 Deployment、Service 等。
这种作用域对集群访问的对象不适用,例如 StorageClass、Node、PersistentVolume 等。
defaultkube-systemkube-publickube-node-lease租约(Lease) 对象使用的命名空间。每个节点都有一个关联的 lease 对象,lease 是一种轻量级资源。lease对象通过发送心跳 ,检测集群中的每个节点是否发生故障。
使用kubectl get lease -A查看lease对象
命名空间是在多个用户之间划分集群资源的一种方法(通过资源配额 )。
不必使用多个命名空间来分隔轻微不同的资源。
例如同一软件的不同版本: 应该使用标签 来区分同一命名空间中的不同资源。
命名空间适用于跨多个团队或项目的场景。
对于只有几到几十个用户的集群,可以不用创建命名空间。
命名空间不能相互嵌套,每个 Kubernetes 资源只能在一个命名空间中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#创建命名空间
kubectl create namespace dev
#查看命名空间
kubectl get ns
#在命名空间内运行Pod
kubectl run nginx --image= nginx --namespace= dev
kubectl run my-nginx --image= nginx -n= dev
#查看命名空间内的Pod
kubectl get pods --n= dev
#查看命名空间内所有对象
kubectl get all
# 删除命名空间会删除命名空间下的所有内容
kubectl delete ns dev
1
2
3
4
5
#查看当前上下文
kubectl config current-context
#将dev设为当前命名空间,后续所有操作都在此命名空间下执行。
kubectl config set-context $( kubectl config current-context) --namespace= dev
卷 | Kubernetes
b站大佬的视频
如果直接将资源或者配置直接保存在pod中会导致两个问题
1.当pod出差重启时会丢失
2.无法统一配置、统一更新
此时就需要数据卷 volume
卷的本质是一个目录 挂载了该卷的pod都可以访问该文件夹
临时卷(Ephemeral Volume):与 Pod 一起创建和删除,生命周期与 Pod 相同
持久卷(Persistent Volume):删除Pod后,持久卷不会被删除
本地存储 - hostPath 、 local
网络存储 - NFS
分布式存储 - Ceph(cephfs 文件存储、rbd 块存储)
关于pv和pvc
pv是由管理者提供的真实的卷 而pvc是使用者的请求 代表他需求的卷
比如 数据卷使用者需要a类型(storageClassName) 的 2Gi 的卷 而数据卷提供者有pv1,pv2,pv3三个满足使用者的需求的卷(pv)
使用者创建对应的pvc去请求卷 卷提供者返回一个符合要求的卷 但具体返回是哪个卷(pv1\2\3) 是不确定的 此时如果需要使用卷 则直接挂载pvc即可(下面的实例)
pv和pvc是一对一绑定 一旦建立了联系 pv就无法被其他pvc使用 一个pvc也无法绑定多个pv
pvc只会绑定大于或等于声明容量的卷
如果不存在满足pvc条件的pv 该pvc会无期限的等待满足条件的pv出现 (集美们千万不要将就.mp3 无端联想)
投射卷(Projected Volumes): projected 卷可以将多个卷映射到同一个目录上
Available 可用 卷是空闲的 尚未被绑定
Bound 已绑定 卷已经被绑定到了pvc
Released 已释放 pvc已被删除 但卷还未被回收
Failed 自动回收失败(local卷不支持自动回收 需要手动删除pv)
ReadWriteOnce 允许被一个节点(node) 以读写方式挂载 并允许同节点上多个pod访问 这是最常用的挂载模式
ReadOnlyMany 允许被多个节点只读挂载 比如多节点共用某个配置时会使用该模式
ReadWriteMany 允许被多个节点读写
ReadWriteOncePod 只允许被单个pod以读写方式挂载 集群中只有一个pod可以读取或写入该pvc 只支持CSI卷 以及需要k8s 1.22+
针对 PV 持久卷,Kubernetes 支持两种卷模式:
volumeMode是一个可选、参数 默认值是Filesystem
Filesystem 卷会被 Pod 挂载到某个目录。 如果卷的存储来自某块设备而该设备目前为空,Kuberneretes 会在第一次挂载卷之前在设备上创建文件系统
Block 将卷作为原始块设备来使用。 这类卷以块设备的方式交给 Pod 使用,其上没有任何文件系统。 这种模式对于为 Pod 提供一种使用最快可能方式来访问卷而言很有帮助, Pod 和卷之间不存在文件系统层。另外,Pod 中运行的应用必须知道如何处理原始块设备 关于如何在 Pod 中使用 volumeMode: Block 的卷, 可参阅原始块卷支持
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
# 创建存储类
apiVersion : storage.k8s.io/v1
kind : StorageClass
metadata :
name : local-storage
provisioner : kubernetes.io/no-provisioner
volumeBindingMode : Immediate
---
apiVersion : v1
# 创建类型为持久卷
kind : PersistentVolume
metadata :
name : local-test
spec :
capacity :
storage : 2Gi
volumeMode : Filesystem
# 访问模式 允许被一个node中的任意多个pod读写
accessModes :
- ReadWriteOnce
persistentVolumeReclaimPolicy : Delete
# 存储卷的类的名称
storageClassName : local-storage
# 挂载的持久卷的类型是local
local :
# 这个目录需要我们在下面指定的node中手动创建
path : /mnt/disks/ssd1
nodeAffinity :
required :
nodeSelectorTerms :
- matchExpressions :
- key : kubernetes.io/hostname
operator : In
values :
# 指定在哪个节点(node)创建
- k3s-agent1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 创建pvc(pv使用申请之类的感觉)
# 告诉卷提供者自己的需求 然后卷提供者提供合适的卷给pvc
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : test-pvc
spec :
# 指定PV的访问模式必须是ReadWriteOnce
accessModes :
- ReadWriteOnce
volumeMode : Filesystem
resources :
requests :
# 需要2Gi 提供者会提供 >=2Gi的 pv
storage : 2Gi
# 指定要local-storage类型的数据卷
storageClassName : local-storage
在pod中使用该数据卷
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# mysql-pod.yaml pod&volume&configMap
apiVersion : v1
kind : Pod
metadata :
name : mysql-pod
labels :
app : mysql
spec :
containers :
- name : mysql
image : mysql:5.7
env :
# mysql镜像初始参数 指定root用户的密码
- name : MYSQL_ROOT_PASSWORD
value : "123456"
volumeMounts :
# 指定容器内 与数据卷映射的目录
- mountPath : /var/lib/mysql
# date-volume 在这里被使用
name : data-volume
# 把下面的mysql-config挂载到容器内的mysql配置文件夹
- mountPath : /etc/mysql/conf.d
name : conf-volume
readOnly : true
volumes :
- name : conf-volume
configMap :
name : mysql-config
- name : data-volume
# 使用pvc作为存储卷 并指定 test-pvc
persistentVolumeClaim :
claimName : test-pvc
---
apiVersion : v1
kind : ConfigMap
metadata :
name : mysql-config
data :
# 它相当一个虚拟的文件夹 里面包含1个文件 mysql.cnf 而文件内容就是'|'后面那些
mysql.cnf : |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
describe看一下 挂载成功了
pod也一定是在k3s-agent1节点下(因为pod指向test-pvc,而调度给pvc的pv被指定到了k3s-agent1)
k8s-静态PV和动态PV - 马里亚纳仰望星空 - 博客园 (cnblogs.com)
注意:该尝试在我k3s的集群并未成功 并且我没有找到错误之所在 如果看到了其中错误欢迎指正
我推测是部署方式的问题
使用kind 基于wsl重新部署后 能正常运行出来 但原本k3s 基于vbox搭的跑不出来
查看存储类 可以看到除了上面创建的local-storage k3s还自带了一个存储类 local-path
1
2
3
4
5
6
7
8
9
10
11
12
apiVersion : v1
kind : PersistentVolumeClaim
metadata :
name : myclaim
spec :
accessModes :
- ReadWriteOnce
# 在这里指定sc的名称 k3s的local-path 或者 kind 的standard
# storageClassName: slow
resources :
requests :
storage : 1Gi
因为local-path的卷绑定模式是 WaitForFirstConsumer 被使用时才创建
所以此时 pvc存在 状态为 Pending 而pv还未创建 此时创建一个挂载了该pvc的pod应该就会创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
apiVersion : v1
kind : Pod
metadata :
name : test-po
spec :
containers :
- name : myfrontend
image : nginx
volumeMounts :
- mountPath : "/var/www/html"
name : mypd
volumes :
- name : mypd
persistentVolumeClaim :
claimName : myclaim
apply应用yaml得到
关于sc存储类 | Kubernetes
使用配置文件对 Kubernetes 对象进行声明式管理 | Kubernetes
YAML规范
配置详解
[模板](# 声明式配置模板)
例如,使用kubectl命令来创建和管理 Kubernetes 对象
命令行就好比口头传达,简单、快速、高效
但它功能有限,不适合复杂场景,操作不容易追溯,适合查询
kubernetes使用yaml文件来描述 Kubernetes 对象
声明式配置就好比申请表,学习难度大且配置麻烦
好处是操作留痕,适合操作复杂的对象,适合修改
使用官方的例子进行声明式创建deploy
1
kubectl apply -f https://k8s.io/examples/application/simple_deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 或者手动复制文件到本地
# simple_deployment.yaml
apiVersion : apps/v1 # Kubernetes API 的版本
kind : Deployment # 对象类别 Pod|Deployment|Service|ReplicaSet|namespace等
metadata: # 描述对象的元数据 'name'&'UID'&'namespace'
name : nginx-deployment
spec: # 对象的配置
selector :
matchLabels :
app : nginx
minReadySeconds : 5
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
可以看到deploy创建成功 image是yaml中指定的 nginx:1.14.2
使用diff命令可以查看将创建的配置信息
1
kubectl diff -f https://k8s.io/examples/application/simple_deployment.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
--- /tmp/LIVE-12789220/apps.v1.Deployment.default.nginx-deployment
+++ /tmp/MERGED-1131175828/apps.v1.Deployment.default.nginx-deployment
@@ -0,0 +1,43 @@
+apiVersion: apps/v1
+kind: Deployment
+metadata:
+ creationTimestamp: "2023-04-17T06:10:50Z"
+ generation: 1
+ name: nginx-deployment
+ namespace: default
+ uid: 5174c7e7-afdd-4ee9-bd1d-2c3e13f2c209
+spec:
+ minReadySeconds: 5
+ progressDeadlineSeconds: 600
+ replicas: 1
+ revisionHistoryLimit: 10
+ selector:
+ matchLabels:
+ app: nginx
+ strategy:
+ rollingUpdate:
+ maxSurge: 25%
+ maxUnavailable: 25%
+ type: RollingUpdate
+ template:
+ metadata:
+ creationTimestamp: null
+ labels:
+ app: nginx
+ spec:
+ containers:
+ - image: nginx:1.14.2
+ imagePullPolicy: IfNotPresent
+ name: nginx
+ ports:
+ - containerPort: 80
+ protocol: TCP
+ resources: {}
+ terminationMessagePath: /dev/termination-log
+ terminationMessagePolicy: File
+ dnsPolicy: ClusterFirst
+ restartPolicy: Always
+ schedulerName: default-scheduler
+ securityContext: {}
+ terminationGracePeriodSeconds: 30
+status: {}
除了根据文件创建也可以根据文件删除
1
kubectl delete -f https://k8s.io/examples/application/simple_deployment.yaml
标签和下面的选择器两章直接复制了k8s-2hours: kubernetes两小时入门教程
虽然自己也去了解了 但感觉大佬的解释比我自己的清楚很多
标签(Labels) 是附加到对象(比如 Pod)上的键值对,用于补充对象的描述信息。
标签使用户能够以松散的方式管理对象映射,而无需客户端存储这些映射。
由于一个集群中可能管理成千上万个容器,我们可以使用标签高效的进行选择和操作容器集合。
键的格式:
有效名称和值:
必须为 63 个字符或更少(可以为空)
如果不为空,必须以字母数字字符([a-z0-9A-Z])开头和结尾
包含破折号-、下划线_、点.和字母或数字
label配置模版
1
2
3
4
5
6
7
8
9
10
11
12
13
apiVersion : v1
kind : Pod
metadata :
name : label-demo
labels : #定义Pod标签
environment : test
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.22
ports :
- containerPort : 80
1
2
3
4
# 查看所有pod及其标签
kubectl get pod --show-labels
# 只查看满足这两个标签的pod
kubectl get pod -l environment = test,app= nginx
标签选择器 可以识别一组对象。标签不支持唯一性
标签选择器最常见的用法是为Service选择一组Pod作为后端
Service配置模版
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
apiVersion : v1
kind : Service
metadata :
name : my-service
spec :
type : NodePort
selector : #与Pod的标签一致
environment : test
app : nginx
ports :
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
- port : 80
targetPort : 80
# 可选字段
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort : 30007
目前支持两种类型的选择运算:基于等值的 和基于集合的 。
多个选择条件使用逗号分隔,相当于And(&&)运算。
1
2
3
4
selector :
matchLabels : # component=redis && version=7.0
component : redis
version : 7.0
类似上面的选择器 不过集合选择是 在一堆里选择
1
2
3
4
5
6
selector :
matchExpressions : # tier in (cache, backend) && environment not in (dev, prod)
# tier == cache || tier == backend
- {key: tier, operator: In, values : [ cache, backend]}
# environment != dev && environment != prod
- {key: environment, operator: NotIn, values : [ dev, prod]}
kind的cri只有docker 不必使用crictl
kind 手动加载镜像示例
1
2
3
4
5
# 先docker拉取镜像
docker pull ist0ne/xtrabackup:1.0
# kind 读取 docker的镜像 ist0ne/xtrabackup:1.0 到集群 wslkindmultinodes
# --name 不写的话它会默认你的集群名字是 kind
kind load docker-image ist0ne/xtrabackup:1.0 --name wslkindmultinodes
cri: 容器运行时接口
crictl是其控制器 用法基本与docker相同 只是crictl少一些功能
1
2
# 比如使用ps查看运行中容器 -a查看所有
crictl ps
ctr导入外部镜像:
导入docker镜像示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 1.下载docker镜像
docker pull alpine:3.17.3
# 2.把镜像打成tar包
docker save apline:3.17.3 > apline-3.17.3.tar
# 3.使用scp等其他命令 把包放入masiter节点
# scp apline-3.17.3.tar root@192.168.56.10
# 使用ctr导入镜像到 k8s.io 的命名空间下
# 使用 --atform linux/amd64 指定容器平台
ctr -n k8s.io images import apline-3.17.3.tar
# 能看到已经存在 alpine:3.17.3 镜像了
crictl images
# 能正常使用 pod状态为CrashLoopBackOff 是因为 alpine不是一个持久化的容器
kubectl run alpine --image= alpine:3.17.3
kubectl describe po alpine
导出
1
2
3
4
5
ctr -n k8s.io images export nginx-1.14.2.tar docker.io/library/nginx:1.14.2 --platform linux/amd64
# ls 看一下成功导出来了
root@k3s-server:~/mhWorkspace/images# ls
apline-3.17.3.tar nginx-1.14.2.tar
1
2
3
mkdir demo02Mysql
# 创建并编辑 mysql-pod 配置文件
vi mysql-pod.yaml
env里的配置就是docker创建容器时的参数 可以在dockerhub里看
mysql - Official Image | Docker Hub
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# mysql-pod.yaml pod&volume
apiVersion : v1
kind : Pod
metadata :
name : mysql-pod
labels :
app : mysql
spec :
containers :
- name : mysql
image : mysql:5.7
env :
# mysql镜像初始参数 指定root用户的密码
- name : MYSQL_ROOT_PASSWORD
value : "123456"
volumeMounts :
# 指定容器内 与数据卷映射的目录
- mountPath : /var/lib/mysql
name : date-volume
volumes :
- name : date-volume
hostPath :
# 宿主机上的目录位置
path : /root/mhWorkspace/data/volumes/mysql
# 此字段为可选 Directory 表示数据卷的类型是个目录(文件夹)
# 选则该值的话需要保证创建时宿主机映射的目录存在 否则会报错
type : DirectoryOrCreate
使用kubectl describe po mysql-pod命令看到我的pod是创建在里agent1上 进入agent1可以看到数据卷已经创建成功了
在k8s中容器可能被部署到任意节点上 此时如果容器需要统一的配置 且配置可能更新 那么就需要在每个节点都单独配置
为了避免麻烦可以使用ConfigMap 来配置
ConfigMap:一个虚拟的数据卷 用于存储可公开的配置 可以被pod挂载使用 可以统一更改 但不该存储私密的配置 也不能存储过大的文件(<1M)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# mysql-pod.yaml pod&volume&configMap
apiVersion : v1
kind : Pod
metadata :
name : mysql-pod
labels :
app : mysql
spec :
containers :
- name : mysql
image : mysql:5.7
env :
# mysql镜像初始参数 指定root用户的密码
- name : MYSQL_ROOT_PASSWORD
value : "123456"
volumeMounts :
# 指定容器内 与数据卷映射的目录
- mountPath : /var/lib/mysql
name : date-volume
# 把下面的mysql-config挂载到容器内的mysql配置文件夹
- mountPath : /etc/mysql/conf.d
name : conf-volume
readOnly : true
volumes :
- name : conf-volume
configMap :
name : mysql-config
- name : date-volume
hostPath :
# 宿主机上的目录位置
path : /root/mhWorkspace/data/volumes/mysql
# 此字段为可选 Directory 表示数据卷的类型是个目录(文件夹)
# 选则该值的话需要保证创建时宿主机映射的目录存在 否则会报错
type : DirectoryOrCreate
---
apiVersion : v1
kind : ConfigMap
metadata :
name : mysql-config
data :
# 它相当一个虚拟的文件夹 里面包含1个文件 mysql.cnf 而文件内容就是'|'后面那些
: |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
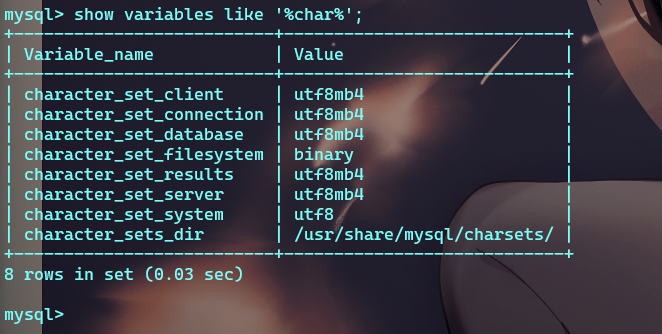
删除之前的pod 重新运行后 进入pod查看mysql的字符集:
1
2
3
4
5
# 查看cm(configMap)
kubectl get cm
# 编辑cm mysql-config 更改后会自动更新所有使用了此配置文件的pod(稍微有点延迟)
kubectl edit cm mysql-config
私密的东西不该存放在ConfigMap 那么如果有就应该存在 Secret里
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
apiVersion : v1
kind : Pod
metadata :
name : mysql-pod
labels :
app : mysql
spec :
containers :
- name : mysql
image : mysql:5.7
env :
# mysql 镜像初始参数 指定root用户的密码
# mysql 通过环境变量存储 密码
- name : MYSQL_ROOT_PASSWORD
valueFrom :
secretKeyRef :
name : mysql-pwd
# key 引用secret的data里的PASSWORD
key : PASSWORD
optional : false
volumeMounts :
# 指定容器内 与数据卷映射的目录
- mountPath : /var/lib/mysql
name : date-volume
# 把下面的mysql-config挂载到容器内的mysql配置文件
- mountPath : /etc/mysql/conf.d
name : conf-volume
readOnly : true
volumes :
- name : conf-volume
configMap :
name : mysql-config
- name : date-volume
hostPath :
# 宿主机上的目录位置
path : /root/mhWorkspace/data/volumes/mysql
# 此字段为可选 Directory 表示数据卷的类型是个目录(文件夹)
# 选则该值的话需要保证创建时宿主机映射的目录存在 否则会报错
type : DirectoryOrCreate
---
apiVersion : v1
kind : ConfigMap
metadata :
name : mysql-config
data :
mysql.cnf : |
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init-connect='SET NAMES utf8mb4'
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
---
apiVersion : v1
kind : Secret
metadata :
name : mysql-pwd
type : Opaque
data :
# data里使用base64加密后的数据 使用命令 echo 123456|base64 转base64
# 明文的数据则存在stringData里
PASSWORD : MTIzNDU2Cg==
1
2
3
# 在mysql中看到环境变量存在 `mysql -uroot -p123456`也正常
root@mysql-pod:/# echo $MYSQL_ROOT_PASSWORD
123456
修改secret
secret的修改要在重启pod后生效
1
kubectl edit secret mysql-pwd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion : v1
data :
# 把root的密码修改成root
PASSWORD : cm9vdAo=
kind : Secret
metadata :
annotations :
kubectl.kubernetes.io/last-applied-configuration : |
{"apiVersion" : "v1" , "data" : {"PASSWORD" : "MTIzNDU2Cg==" }, "kind" : "Secret" , "metadata" : {"annotations" : {}, "name" : "mysql-pwd" , "namespace" : "default" }, "type" : "Opaque" }
creationTimestamp : "2023-05-07T03:40:05Z"
name : mysql-pwd
namespace : default
resourceVersion : "79325"
uid : 37e1a144-cba5-427a-aeb1-4c0999a1a6bd
type : Opaque
重启pod
1
kubectl get pod { podname} -n { namespace} -o yaml | kubectl replace --force -f -
1
2
3
# 再打印密码就是root了
root@mysql-pod:/# echo $MYSQL_ROOT_PASSWORD
root
注: 这个东西比较复杂 不要求完全理解 后面会使用helm自动部署
推荐详解视频:MySQL主从复制_哔哩哔哩_bilibili
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
# mysql-configmap 为主服务器和副服务器提供不同的配置
apiVersion : v1
kind : ConfigMap
metadata :
name : mysql
labels :
app : mysql
app.kubernetes.io/name : mysql
data :
primary.cnf : |
# 仅在主服务器上应用此配置
[mysqld]
log-bin
replica.cnf : |
# 仅在副本服务器上应用此配置
[mysqld]
super-read-only
---
# 为 StatefulSet 成员提供稳定的 DNS 表项的无头服务(Headless Service)
apiVersion : v1
kind : Service
metadata :
name : mysql
labels :
app : mysql
app.kubernetes.io/name : mysql
spec :
ports :
- name : mysql
port : 3306
clusterIP : None
selector :
app : mysql
---
# 用于连接到任一 MySQL 实例执行读操作的客户端服务
# 对于写操作,你必须连接到主服务器:mysql-0.mysql
apiVersion : v1
kind : Service
metadata :
name : mysql-read
labels :
app : mysql
app.kubernetes.io/name : mysql
# 打了一个只读的标签
readonly : "true"
spec :
ports :
- name : mysql
port : 3306
selector :
app : mysql
---
# sts
apiVersion : apps/v1
kind : StatefulSet
metadata :
name : mysql
spec :
selector :
matchLabels :
app : mysql
app.kubernetes.io/name : mysql
serviceName : mysql
replicas : 3
template :
metadata :
labels :
app : mysql
app.kubernetes.io/name : mysql
spec :
# Init 容器 在容器启动之前干一些事情的容器
initContainers :
- name : init-mysql
image : mysql:5.7-debian
command :
- bash
- "-c"
- |
set -ex
# 基于 Pod 序号生成 MySQL 服务器的 ID。
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 添加偏移量以避免使用 server-id=0 这一保留值。
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 将合适的 conf.d 文件从 config-map 复制到 emptyDir。
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts :
- name : conf
mountPath : /mnt/conf.d
- name : config-map
mountPath : /mnt/config-map
- name : clone-mysql
image : ist0ne/xtrabackup:1.0
command :
- bash
- "-c"
- |
set -ex
# 如果已有数据,则跳过克隆。
[[ -d /var/lib/mysql/mysql ]] && exit 0
# 跳过主实例(mysql-0)的克隆。
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 从原来的对等节点克隆数据。
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 准备备份。
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
containers :
- name : mysql
image : mysql:5.7-debian
env :
- name : MYSQL_ALLOW_EMPTY_PASSWORD
value : "1"
ports :
- name : mysql
containerPort : 3306
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
resources :
requests :
cpu : 500m
memory : 1Gi
livenessProbe :
exec :
command : [ "mysqladmin" , "ping" ]
initialDelaySeconds : 30
periodSeconds : 10
timeoutSeconds : 5
readinessProbe :
exec :
# 检查我们是否可以通过 TCP 执行查询(skip-networking 是关闭的)
command : [ "mysql" , "-h" , "127.0.0.1" , "-e" , "SELECT 1" ]
initialDelaySeconds : 5
periodSeconds : 2
timeoutSeconds : 1
- name : xtrabackup
image : ist0ne/xtrabackup:1.0
ports :
- name : xtrabackup
containerPort : 3307
command :
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 确定克隆数据的 binlog 位置(如果有的话)。
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup 已经生成了部分的 “CHANGE MASTER TO” 查询
# 因为我们从一个现有副本进行克隆。(需要删除末尾的分号!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# 在这里要忽略 xtrabackup_binlog_info (它是没用的)。
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 我们直接从主实例进行克隆。解析 binlog 位置。
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 检查我们是否需要通过启动复制来完成克隆。
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# 如果容器重新启动,最多尝试一次。
mv change_master_to.sql.in change_master_to.sql.orig
fi
# 当对等点请求时,启动服务器发送备份。
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
resources :
requests :
cpu : 100m
memory : 100Mi
volumes :
- name : conf
emptyDir : {}
- name : config-map
configMap :
name : mysql
volumeClaimTemplates :
- metadata :
name : data
spec :
accessModes : [ "ReadWriteOnce" ]
resources :
requests :
storage : 2Gi
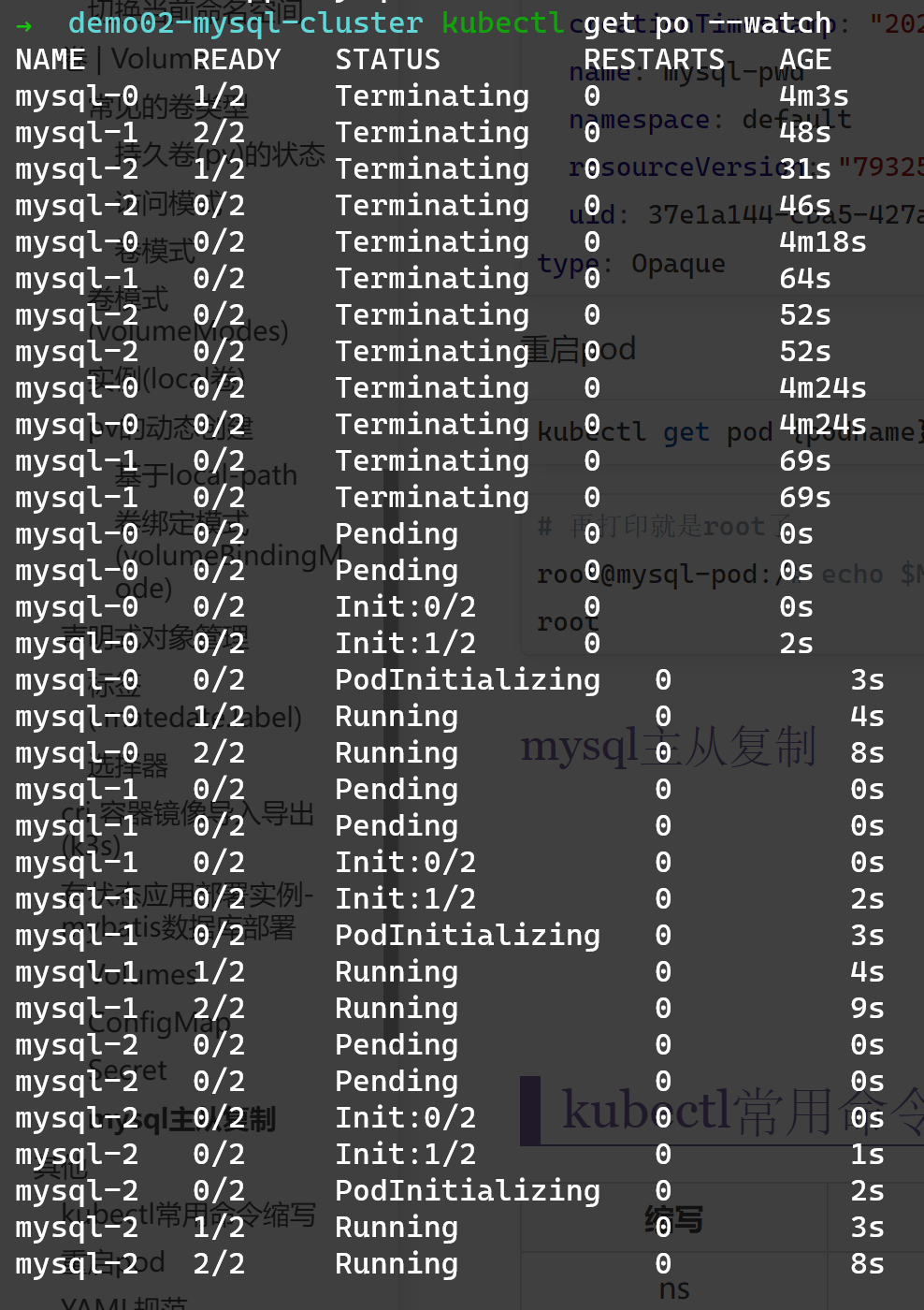
在整个启动过程中 可以看到 在每个pod启动前 都有: init:0/2
这个init指的是 init容器 它是一种特殊容器 它会在pod运行前运行 如果运行失败pod就不会运行
它通常用于
生成配置文件
执行初始化命令或脚本
执行健康检查(检查依赖的服务是否在正常)
在上面的例子中 init容器共有两个 分别是init-mysql和clone-mysql
init-mysql:
它的作用是给节点选择正确的配置文件(ConfigMap中有无写权限写了两份配置)
clone-mysql:
它的作用是给非主节点发送从上一个节点备份的初始数据 会直接跳过0节点(mysql-0是主节点 它是唯一写入数据的主数据库)
在它运行时 上一个pod已经创建xtrabackup(边车,细解在下面)也已经实现了数据的备份 并且子节点的容器还没创建 还没有自己的MySQL数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
initContainers :
- name : init-mysql
image : mysql:5.7-debian
command :
- bash
- "-c"
- |
set -ex
# 基于 Pod 序号生成 MySQL 服务器的 ID。
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# 添加偏移量以避免使用 server-id=0 这一保留值。
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# 将合适的 conf.d 文件从 config-map 复制到 emptyDir。
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts :
- name : conf
mountPath : /mnt/conf.d
- name : config-map
mountPath : /mnt/config-map
- name : clone-mysql
image : ist0ne/xtrabackup:1.0
command :
- bash
- "-c"
- |
set -ex
# 如果已有数据,则跳过克隆
[[ -d /var/lib/mysql/mysql ]] && exit 0
# 跳过主实例(mysql-0)的克隆
[[ `hostname` =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# 从原来的对等节点克隆数据 $ordinal只当前节点序号 减1就是从上一个节点复制
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# 准备备份。
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts :
- name : data
mountPath : /var/lib/mysql
subPath : mysql
- name : conf
mountPath : /etc/mysql/conf.d
参考:
Init 容器 | Kubernetes
边车是指在容器外部的为容器提供某些功能的辅助容器 包括:监视、日志记录、限流、熔断、服务注册、协议适配转换等
在主从复制的例子中 我们在containers中创建了两个容器 一个是mysql主服务 另一个作为辅助工具(mysql备份工具)的xtrabackup容器就是边车
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
containers :
- name : xtrabackup
image : ist0ne/xtrabackup:1.0
ports :
- name : xtrabackup
containerPort : 3307
command :
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# 确定克隆数据的 binlog 位置(如果有的话)
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup 已经生成了部分的 “CHANGE MASTER TO” 查询
# 因为我们从一个现有副本进行克隆。(需要删除末尾的分号!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# 在这里要忽略 xtrabackup_binlog_info (它是没用的)。
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# 我们直接从主实例进行克隆。解析 binlog 位置。
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# 检查我们是否需要通过启动复制来完成克隆。
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# 如果容器重新启动,最多尝试一次。
mv change_master_to.sql.in change_master_to.sql.orig
fi
# 当对等点请求时,启动服务器发送备份。
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
通常集群数据库的端口不对外暴露 但为了调试我们可以使用port-forward命令
1
kubectl port-forward mysql-0 --address= 127.0.0.1 33060:3306
这是一个持续运行的命令 退出命令端口就关了
Helm 中文文档 | Docs
Artifact Hub 远程仓库 类似于dockerHub
Helm 是 Kubernetes 的软件包管理工具
类似于我们在 Ubuntu 中使用的apt,Centos中使用的yum一样,能快速查找和安装软件包
Helm使用chart来封装kubernetes应用的YAML文件,我们只需要设置自己的参数,就可以实现自动化的快速部署应用
helm 是一个命令行工具,用于本地开发及管理chart,chart仓库管理等chart Helm的包 它包含所有资源的定义和依赖 类似maven的pom.xml go.mod之类的 描述了一组相关的 k8s 集群资源release 使用 helm install 命令在 Kubernetes 集群中部署的 Chart 称为 Release 类似chart是镜像 release是容器Repoistory helm chart的仓库
国内环境推荐使用二进制版本安装
Helm | 安装Helm
k3s部署的要使用这个命令来配置config文件
1
export KUBECONFIG = /etc/rancher/k3s/k3s.yaml
因为一般这个配置在$HOME/.kube/config
以mysql为例
在Artifact Hub 中搜索mysql 然后点进第一个 Bitnami的mysql
右边的 install 是使用的命令
values schema 是可配置参数
1
2
3
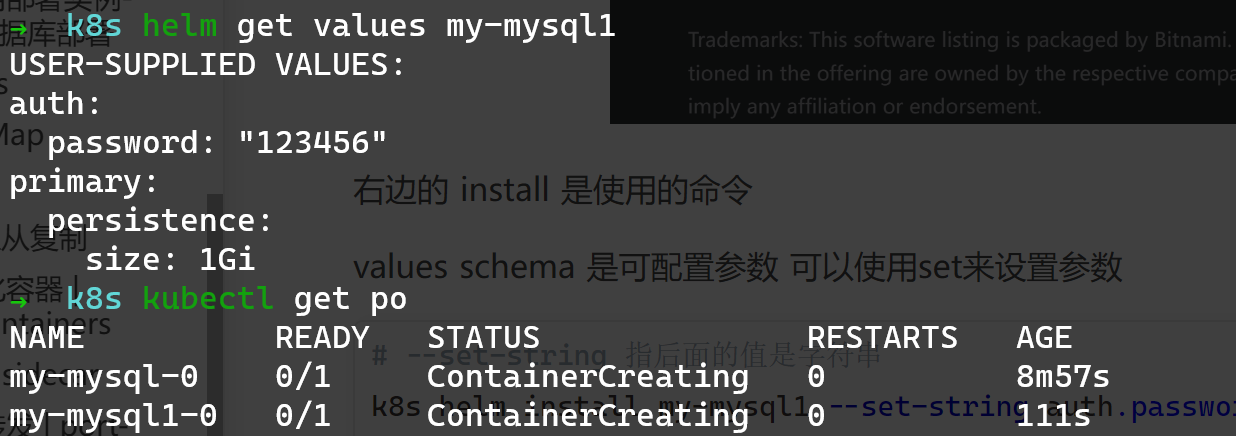
# --set-string 指后面的值是字符串
k8s helm install my-mysql1 --set-string auth.password= 123456 --set primary.persistence.size= 1Gi bitnami/mysql --versi
on 9.9.1
使用
1
helm get values RELEASE_NAME
可以看到自己设置的配置信息
建立了之后可以直接在kubectl中看到节点
1
2
# 使用命令删除my-mysql1
helm delete my-mysql1
bitnami/mysql:8.0.33-debian-11-r7的镜像载不下来 一直是ContainerCreating的状态
因为镜像载不下来的问题 我没有验证它
请参照大佬的视频 Helm安装MySQL主从集群_哔哩哔哩_bilibili
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
auth :
rootPassword : "123456"
# Primary database configuration
primary :
# Enable persistence using Persistent Volume Claims
persistence :
size : 1Gi
# If true, use a Persistent Volume Claim, If false, use emptyDir
enabled : true
# Secondary database configuration
secondary :
replicaCount : 2
# Enable persistence using Persistent Volume Claims
persistence :
size : 1Gi
# If true, use a Persistent Volume Claim, If false, use emptyDir
enabled : true
architecture : replication
缩写
名称
ns
namespaces
no
nodes
po
pods
svc
services
deploy
deployments
rs
replicasets
sts
statefulset
hpa
Horizontal Pod Autoscaler | Pod缩放策略
cm
configMap
ev
Ephemeral Volume | 临时卷
pv
Persistent Volume | 持久卷
pvc
PersistentVolumeClaim | 持久卷声明
Projected Volumes | 投射卷
sc
StorageClass | 存储类
k8s 重启pod |weixin_39768917的博客 | CSDN博客
YAML 入门教程 | 菜鸟教程 (runoob.com)
缩进代表上下级关系
缩进时不允许使用Tab键,只允许使用空格,通常缩进2个空格
: 键值对,后面必须有空格
-数组,后面必须有空格
#注释
| 多行文本块
— 表示文档的开始,多用于分割多个资源对象 k8s中常用于分割创建的两种对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# 这是注释
group :
name : group-1
members :
- name : "Jack Ma"
UID : 10001
- name : "Lei Jun"
UID : 10002
# 也可以写成
# words:
# - "I don't care money"
# - "R U OK"
words :
[ "I don't care money" , "R U OK" ]
text : |
line
new line
3rd line
---
group :
name : group-2
members :
- name : "Jack Mi"
UID : 10001
- name : "Li Jun"
UID : 10002
words :
[ "要不要进我的妙妙屋" ]
# comments
text : |
第一行
第二行
第三行
使用配置文件对 Kubernetes 对象进行声明式管理 | Kubernetes
使用 kubectl explain命令来获取配置属性帮助
该命令是声明式配置的最详细、最方便的解
对于声明式对象管理 中的yaml文件 想要获取 selector 下的所有可选配置
1
kubectl explain deploy.spec.selector
其中 deploy 是想要创建的目标类型(因为不同的类型有不同的配置,例如 deploy 可以配置更新策略 而po则不需要)
spec.selector 则是文件中的上下级关系 这里指 spec 下的 selector 想要更下层的信息则可以继续加点 比如 kubectl explain deploy.spec.selector.matchLabels
k8s集群api版本
官方详解 | 配置 API | Kubernetes
使用kubectl api-versions命令查看 所有可选版本
基本上选择apps/v1 它包含一些通用的应用层的api组合,如:Deployments, RollingUpdates, and ReplicaSets
目标类型
基本上就是命令那些( Pod|Deployment|Service|ReplicaSet|namespace )
更多的请看这篇 k8s的yaml文件中kind类型详解 - 掘金 (juejin.cn)
以及官方说明 (但愿能对您有所帮助 俺看不来英语QxQ)
元数据 以下只列举一些常用的
所有配置请看:ObjectMeta | 可选配置 | Kubernetes
name : <string>
命名空间内唯一 不可更新
namespace : <string>
指定命名空间
annotations : <map[string]string>
以 key:value 的形式 写一些给人类看而非机器看的注解
1
2
3
4
metadata :
annotations :
imageregistry : "https://hub.docker.com/" # 告诉读者 使用的镜像仓库是 dockerhub
mhqdz : "真ikun" # 告诉读者 mhqdz是真ikun (OwO)
labels : <map[string]string>
格式同上面的annotations
但它是给机器看的
标签的动机是使用户能够以松散耦合的方式将他们自己的组织结构映射到系统对象,而无需客户端存储这些映射
可用于组织和分类(确定范围和选择)对象的字符串键和值的映射。 可以匹配 ReplicationController 和 Service 的选择算符
标签和选择算符 | Kubernetes
推荐使用的标签 | Kubernetes
spec:
# 新创建的pod在没有任何容器崩溃的情况下准备就绪的最小秒数。因为它被认为是可用的。默认为0 (pod一旦准备好就会被认为可用)
minReadySeconds: <integer>
# 是否暂停部署
paused: <boolean>
# deploy 部署的最大时间 超过最大时间没有部署完成,就会变成超时状态 默认600s
progressDeadlineSeconds: <integer>
# 所需节点数
replicas: <integer>
# 版本更新后 保留的旧版本rs数量 默认为10
revisionHistoryLimit: <integer>
# 标签选择器
selector: <object>
# deploy的更新策略 详见下面的 deploy.spec.strategy
strategy: <object>
# 对pod的配置
template: <object>
metadata: <object>
spec: <Object>
deploy.spec.strategy
deploy.spec.selector
感觉就是声明pod的label 但不知道在这里写 和deploy.spec.template.metadata.labels有什么区别
详见标签和选择算符 | 在 API 对象中设置引用 | Kubernetes
1
2
3
4
5
6
7
8
9
10
11
12
13
spec :
# strategy deploy的更新策略
strategy :
# 可选值为 Recreate 和 RollingUpdate 默认值为 RollingUpdate
# Recreate 推倒重来 删了所有旧的po 然后建新的 会导致服务短暂不可用
# RollingUpdate 滚动更新 详见上面的deploy篇
type: Recreate | RollingUpdate
# rollingUpdate 对滚动更新的手动配置 当type=Recreate时 不能使用该参数
rollingUpdate :
# maxSurge 可以调度的pod的最大数量超过所需的pod数量 详见下
maxSurge: <string>
# maxUnavailable 更新期间不可用的pod的最大数量 详见下
maxUnavailable: <string>
**maxSurge:**可以调度的pod的最大数量超过所需的pod数量 值可以是一个绝对值(例如:5)或所需pod的百分比(例如:10%) 绝对数由百分数四舍五入计算得出
示例:当该值设置为30%时,新的ReplicaSet可以在滚动更新开始时立即扩展,这样新旧pod的总数不会超过所需pod的130%。一旦旧的pod被杀死,新的ReplicaSet可以进一步扩展,确保在更新期间任何时间运行的pod总数最多为所需pod的130%
**maxUnavailable:**在更新期间不可用的pod的最大数量 价值可以是绝对数量(例如:5)或所需pod的百分比(例如:10%) 绝对数是按百分比按四舍五入计算的
例如:当这个值设置为30%时,当滚动更新开始时,旧的ReplicaSet可以立即缩放到所需pod的70% 一旦新的pod准备好了,就可以进一步缩小旧的ReplicaSet,然后再扩大新的ReplicaSet,确保在更新期间可用的pod总数至少是所需pod的70%
maxSurge|maxUnavailable 默认值均为25% 且不能同时为0
[回到声明式对象管理](# 声明式对象管理)
Pod | Kubernetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
apiVersion : v1
kind : Pod
metadata :
name : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
# --port=80
- containerPort : 80
# 关于卷(volume)的配置 详见下面
volumeMounts :
# 容器内部映射的目录 如 mysql是 /var/lib/mysql
# 一般在dockerhub的文档里有挂载数据的例子 跟那个一样就行
- mountPath : /test-pd
# test-volume 根据数据卷的名称被调用
name : test-volume
volumes :
# 数据卷的名称 类似var了个变量的感觉?
- name : test-volume
# 以hostPath为例 详见下面的官方文档
hostPath :
# 宿主机上的目录位置
path : /data
# 此字段为可选 可选字段如下
type : Directory
取值
行为
空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查
DirectoryOrCreate
path指向目录 如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息
Directory
path指向目录 且该目录必须存在
FileOrCreate
path指向文件 如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权
File
path指向文件 且该文件必须存在
Socket
指向必须存在的UNIX 套接字 如 /var/run/docker.sock进程
CharDevice
指向必须存在的字符设备
BlockDevice
指向必须存在的块设备
卷 | Kubernetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# simple_deployment.yaml
apiVersion : apps/v1 # Kubernetes API 的版本
kind : Deployment # 对象类别 Pod|Deployment|Service|ReplicaSet|namespace等
metadata: # 描述对象的元数据 'name'&'UID'&'namespace'
name : nginx-deployment
spec: # 对象的配置
selector :
matchLabels :
app : nginx
minReadySeconds : 5
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
Service | Kubernetes
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
apiVersion : v1
kind : Service
metadata :
name : ngs-svc
spec :
type : NodePort
selector :
# 标签选择器 选择提供服务的pod
# 注意区分大小写
app : nginx
ports :
# port 服务端口
- port : 80
# targetPort 容器端口
# 默认情况下,为了方便起见,`targetPort` 被设置为与 `port` 字段相同的值。
targetPort : 80
# 可选字段
# 对外公开的端口
# 默认情况下,为了方便起见,Kubernetes 控制平面会从某个范围内分配一个端口号(默认:30000-32767)
nodePort : 30007
[回到声明式对象管理](# 声明式对象管理)
apiVersion: v1
kind: Namespace
metadata:
name: dev
labels:
name: dev
ConfigMap | Kubernetes
mysql实例
金丝雀发布(Canary Release)
版本更新时使用一部分新版本节点加入旧版本的集群 给用户使用 然后逐渐增加新版本的比例 直至所有旧版本都被替换
首先创建一个yaml文件 deploy-v1.yaml
它创建了命名空间ngs-ns及在该命名空间下的delpoyngs-v1和服务ngs-svc-v1
代表旧版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# deploy-v1.yaml
apiVersion : v1
kind : Namespace
metadata :
name : ngs-ns
---
apiVersion : apps/v1
kind : Deployment
metadata :
name : ngs-v1
namespace : ngs-ns
spec :
selector :
matchLabels :
app : nginx
replicas : 3
template :
metadata :
labels :
app : nginx
spec :
containers :
- name : nginx
image : nginx:1.14.2
ports :
- containerPort : 80
---
apiVersion : v1
kind : Service
metadata :
name : ngs-svc-v1
namespace : ngs-ns
spec :
type : NodePort
selector :
app : nginx
ports :
- port : 80
targetPort : 80
nodePort : 30007
1
2
3
4
5
# apply yaml文件
kubectl apply -f deploy-v1.yaml
# 切换命名空间到 ngs-ns
# 当然也可以在每条命令后面加入 -n=ngs-ns 表示在ngs-ns里执行
kubectl config set-context --current --namespace= ngs-ns
创建deploy-v2.yaml 在里面声明一个新的deploy ngs-v2-canary
该deploy基于docker/getting-started镜像 同时也满v1版本服务的选择器 app=nginx
所以会自动加入原本的服务
使用curl命令能访问到两种不同的结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
apiVersion : apps/v1
kind : Deployment
metadata :
name : ngs-v2-canary
namespace : ngs-ns
spec :
selector :
matchLabels :
app : nginx
replicas : 1
template :
metadata :
labels :
# 因为新的版本也满足选择器 app=nginx 所以也会自动加入到service中
app : nginx
# 加入一个跟踪标签 方便查找
trackk : canary
spec :
containers :
- name : new-nginx
image : docker/getting-started
ports :
- containerPort : 80
假设此时我们已经确定新版本(ngs-v2-canary)已经可以正常运行
那么则继续扩大 新版本范围 并停用旧版本
1
2
kubectl scale deploy ngs-v2-canary --replicas= 3
kubectl scale deploy ngs-v1 --replicas= 0
完全替换之后就完成了一次金丝雀发布